1、优化背景
最近在做一个隐私号相关的服务,其中一个主要的接口遇到了性能瓶颈,本文把优化的思路、过程和结果记录下来,以供备忘和之后参考。
基础概念
隐私号服务:隐私保护通话(Private Number),针对企业的各种商业场景,在不增加SIM卡的情况下,为企业的用户增加隐私号码,使其既能享受优质的通话和短信服务,又能隐藏真实号码,保护个人隐私。—华为云
AXB:三个号码的绑定关系,其中X为隐私号码,A号码和B号码之间通过X号码进行通话。比如,在打车场景下,司机端为A号码,乘客端为B号码,之间通过X号码通话,两端看到的也都是X号码。(PS. 此处先不引入透传概念)
AX:两个号码的绑定关系,其中X为隐私号码,任意B号码呼叫X号码,都可以呼叫到A号码。
绑定冲突:假设同时存在号码A1X1B1与A1X1B2,那么A1拨打X1的时候,就不知道应该转给B1还是B2了,这种情况就是一种绑定冲突。同理假设同时存在A2X2与A3X2,也会出现绑定冲突。
所以在同一个X号码的前提下,旧AXB关系中AB不允许与该X建立任何关系,旧AX关系中的X不允许建立任何关系,如下所示:
| 新AXB关系 | 新AX关系 | |
|---|---|---|
| 旧AXB关系 | AB号码有一个相同即冲突 | 冲突 |
| 旧AX关系 | 冲突 | 冲突 |
2、接口逻辑
隐私号服务提供绑定接口,该接口既支持AX绑定,也支持AXB绑定,除了要建立绑定关系之外,还要进行绑定冲突的校验,保证数据的正确性。主要逻辑如下所示:
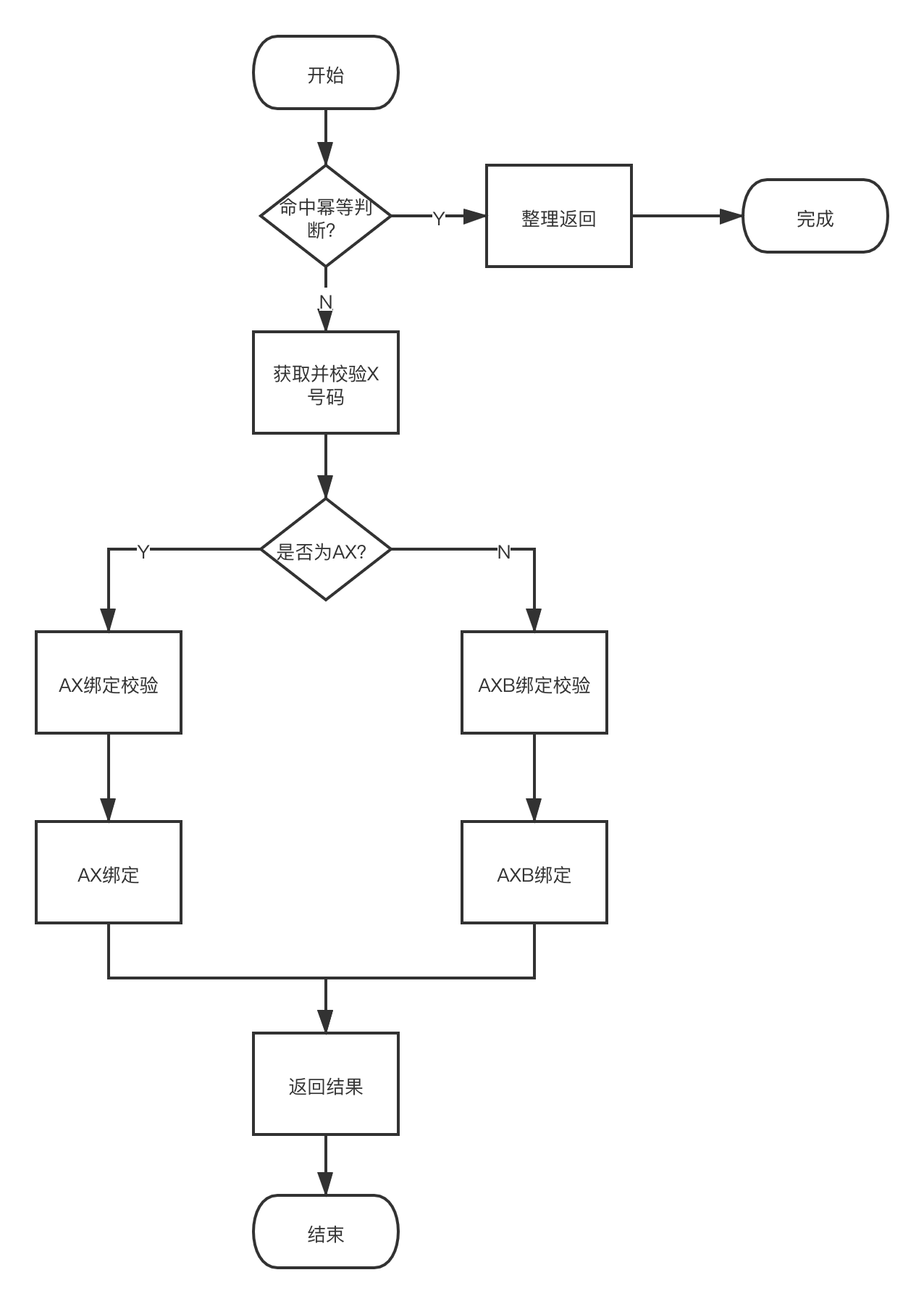
如上图所示,主要逻辑包括幂等校验和冲突校验,且全部借助DB实现,简略版sql(忽略过期时间等附加参数)如下所示:
幂等校验
select * from 绑定关系表 where 状态 = 已绑定 and A = A and X = X and B = BAX冲突校验
select * from 绑定关系表 where 状态 = 已绑定 and X = X and B = ''AXB冲突校验
select * from 绑定关系表 where 状态 = 已绑定 and X = X and (A in (A, B) or B in (A, B))
这种完全依赖DB的方式简单且易懂,但是在绑定关系表数量达到一定值且QPS也升上来时,这种单纯依赖DB的做法就显得力不从心了。一是DB比较脆弱QPS升上来时,DB的cpu飙升;二是随着绑定关系数量的增多,虽然有索引加持,但是QPS的压力全落在DB上,还是很容易出现慢sql,而且一旦出现慢sql,用户就会重试导致qps增高,DB就崩溃了,从而产生恶性循环最终导致整个服务的不可用。
3、 优化策略
经过以上分析,我们很容易判断出性能瓶颈就是在DB上,所以优化的思路就围绕着减轻DB压力展开了。
- 幂等校验转移到缓存中,减轻DB压力
- 绑定冲突校验转移到缓存中,减轻DB压力
- 建立定时清理无效数据的机制,保证表记录在一个健康的级别内
- 建立用户级别的QPS限制机制,避免因为个别用户导致整体服务不可用
其中3和4都是辅助机制,本文中就不在详细描述了。
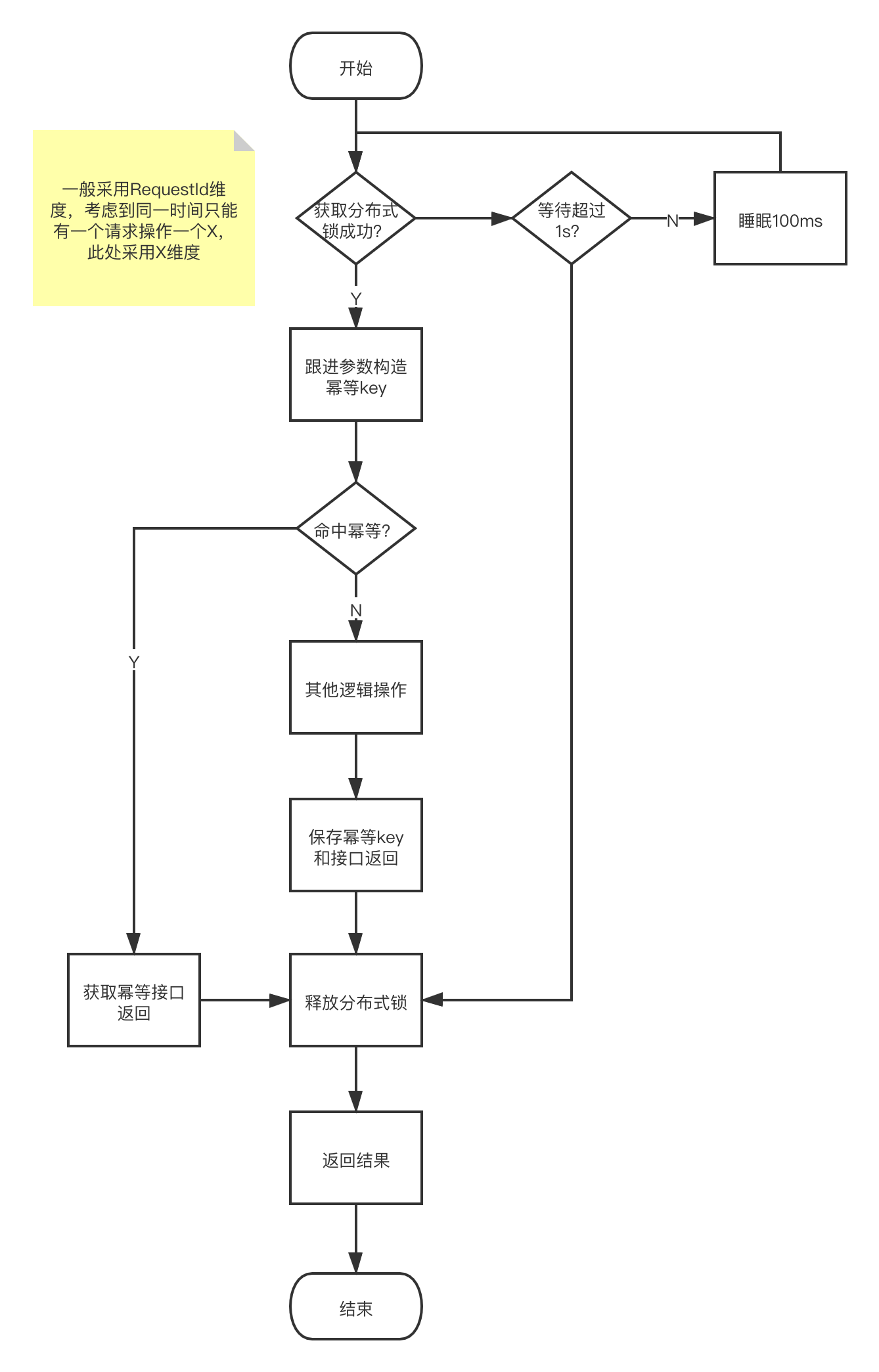
3.1 幂等校验
如果现在去谷歌一下,相信可以找到很多现成方案,这里就不详细列举和对比每个方案的不同了,最后实现了一个比较成熟合适的方案如下:
3.2 冲突校验
冲突校验比较特殊,没有成熟的方案用来参考,但是基本思路是一致的,就是减轻DB压力,把冲突校验也转移到缓存上来实现。
想出的方案大概有两种:
把XA和XB关系作为key
例一:
1 新增A1X1B1时,缓存中新增X1A1和X1B1
2 新增A2X1时,需在db判断
3 新增A1X1B2时,因为缓存存在X1A1,则冲突
4 新增A2X1B2时,缓存不存在X1A2、X1B2和X1,则不冲突
例二:
1 新增A1X1时,缓存中新增X1
2 新增A2X1时,因为缓存存在X1,则冲突
3 新增A2X1B2时,因为缓存存在X1,则冲突
优点:
- 可以针对单独的绑定关系设置过期时间
缺点:
- 无法判断是否存在AX绑定关系,即无法处理添加AX时的情况
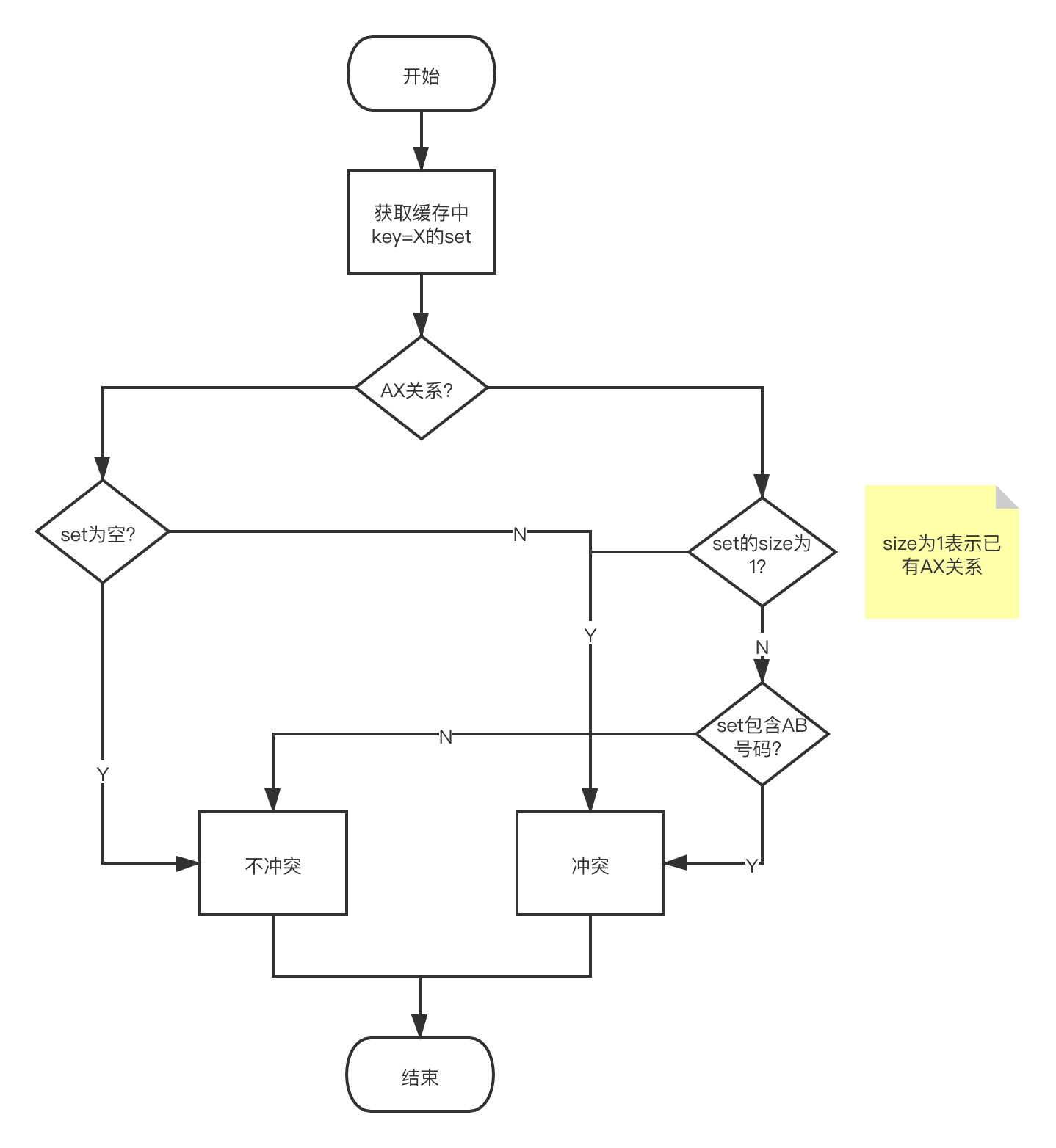
用X号码做key,维护一个set,set的内容为AB号码
例一:
1 新增A1X1B1时,redis中新增 X1=[A1,B1]
2 新增A2X1时,判断redis中的X1中只要有值就算冲突
3 新增A1X1B2时,因为redis的X1中已经存在A1,则冲突
4 新增A2X1B2时,redis的X1中不存在A2和B1,则不冲突
例二:
1 新增A1X1时,redis中新增X1=[A1]
2 新增A2X1时,因为redis的X1中有值,则冲突
3 新增A2X1B2时,因为redis的X1中只有一个值,为旧有AX关系,则冲突
优点:
- 可以处理AX的情况
缺点:
- 数据维护过程比较复杂
经过对比和讨论,最终采用方案2,流程图如下:
4 优化总结
经过以上的优化,在保证接口的响应时长不变的前提下,最大QPS上升了一个数量级,具体的数值不方便列举。随着业务的增长也可以通过横向增加实例数量来支撑了,但是如果想在上一个数量级的话,DB还会成为瓶颈,可能就得考虑分库或者单独部署了。
碍于篇幅,一些不太重要的地方没有在本文中一一列出,感兴趣的同学也可以email我。
好久没写博客了,希望本文可以给你带来一点点帮助,也希望我可以平衡工作和生活吧。